
Web scraping
Cortex Click provides a web scraper that is optimized for parsing and cleaning data for LLM consumption. It automatically transforms content into markdown, cleans redundant sections like nav headers and sidebars, and resolves images and links to fully qualified paths. This enables the intelligent content engine to insert images and citations from your website automatically.
Scraping individual URLs
Upsert one or more URLs for web scraping. Upserting URLs returns immediately with a 202 accepted, and scraping and indexing happens asynchronously.
const docs: UrlDocument[] = [
{
url: "https://www.cortexclick.com/",
contentType: "url",
},
];
await catalog.upsertDocuments(docs);Scraping sitemaps
Upsert one or more sitemap documents to scrape and index an entire website. Sitemaps and sitemap indexes will be recursively traversed. Upserting sitemaps returns immediately with a 202 accepted, and scraping and indexing happens asynchronously.
const docs: SitemapDocument[] = [
{
sitemapUrl: "https://www.cortexclick.com/sitemap.xml",
contentType: "sitemap-url",
},
];
await catalog.upsertDocuments(docs);Automatic indexing using web scraper indexer
From a catalog page, you can create a web scraper indexer to automatically update your content. Indexers can run on daily, weekly, or monthly. You can also run an indexer on demand at any time. Scroll down to the bottom of the page to find the Indexers section, and choose "Create indexer to scrape urls and sitemaps" option.
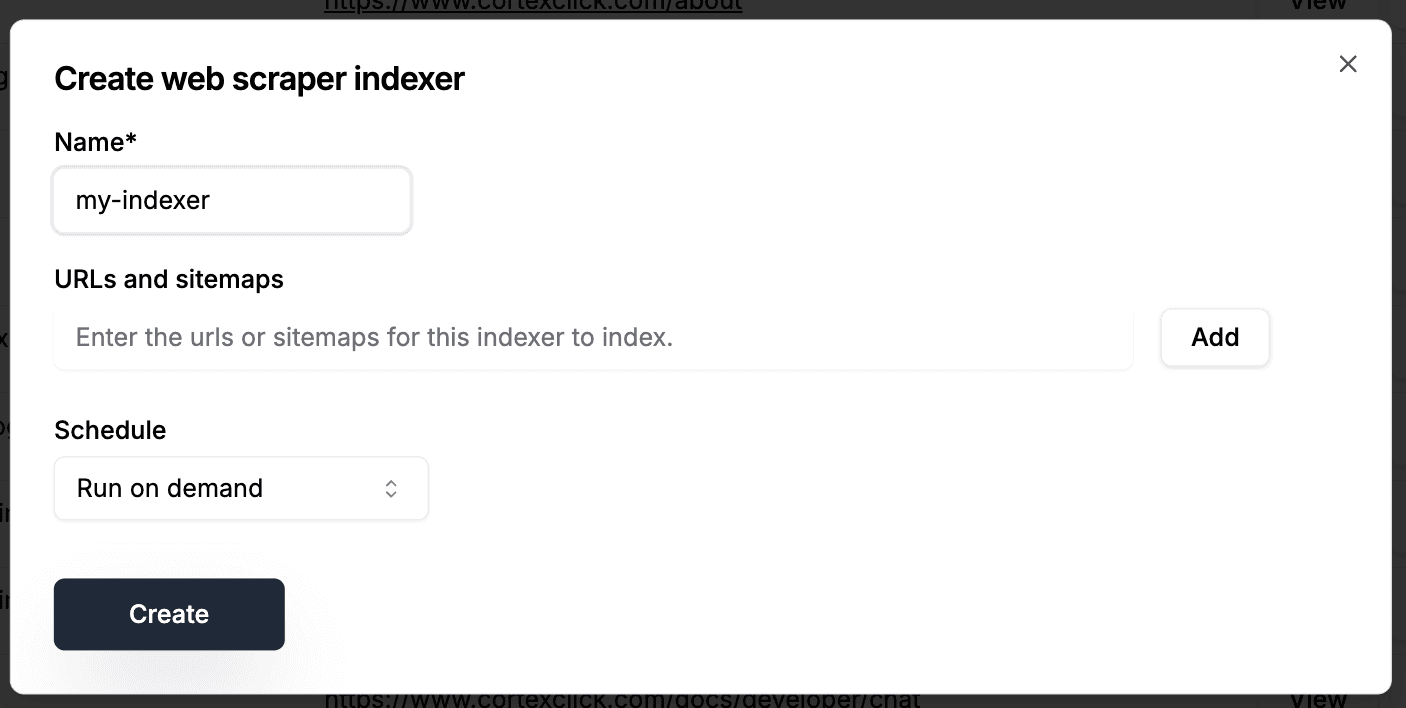
You can also create, run, and manage indexers using the SDK:
// Create an indexer
const indexer = await client.createWebScraperIndexer(
"my-indexer",
"my-catalog",
IndexerScheduleFrequency.OnDemand,
{
urls: ["https://www.example.org"],
sitemaps: ["https://www.example.org/sitemap.xml"],
},
);
// Get an indexer
const myIndexer = await client.getIndexer("my-indexer");
// Run an indexer and wait for it to complete
// (you can also run the indexer without waiting for completion by calling myIndexer.run() )
const result = await myIndexer.run({ waitForCompletion: true });
if (result.status === "failure") {
console.error("Indexer execution failed", result.errors);
}
// Get the indexer execution history - it contains the results of the latest 100 runs
const history = await myIndexer.getExecutionHistory();
history.results.forEach((result) => {
console.log(`Status: ${result.status}`);
console.log(`Start Time UTC: ${result.startTimeUtc}`);
console.log(`End Time UTC: ${result.endTimeUtc ?? 'N/A'}`);
console.log(`Errors: ${result.errors.join(', ')}`);
console.log(`Warnings: ${result.warnings.join(', ')}`);
console.log('---');
});
// Delete an indexer
await myIndexer.delete();